
Data modeling in Apache Hadoop
CONFERENCE ROOM
24th November, 16:50-17:20
Today, organizations are making their decisions based on data.
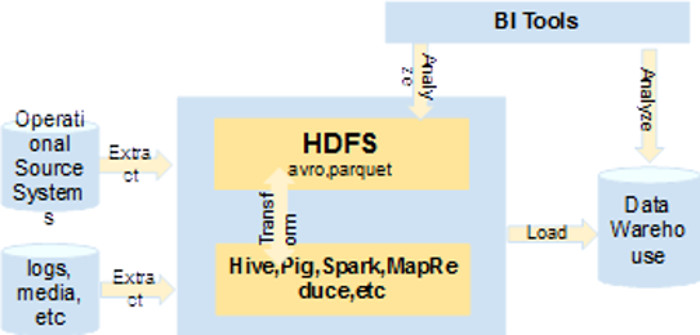
One of the first steps in your data infrastructure is to decide how to store, model and process your data.
Using a public dataset, MovieLens, we are going to work on a batch processing case study, namely on a movie rating system.
Through this use case, we will see all the steps involved in storing and modeling your data into a Hadoop infrastructure, technologies involved and how Apache Hadoop can complement your Data Warehouse solution.

Tudor Lăpușan
Telenav
I'm passionate about bigdata technologies, especially Apache Hadoop. I heard for the first time about Apache Hadoop when I was at my master courses and from that time I was fascinated about bigdata world. My first big professional success was when I introduced the Apache Hadoop technology into the company I'm working for, skobbler, in 2012. From that time I'm working as a full time devops on bigdata projects. My current work involve to well manage and maintain the Hadoop and Hbase in-house clusters. From this passion, I have initiated a bigdata/data science community in my town, Cluj-Napoca, Romania, with the goals of meeting new passionate people, working together on cool projects and helping IT companies to adopt BigData technologies. Until now we had many meetups and workshops with many participants. "


